
Per tutto il mese di febbraio la Lombardia è stata in zona gialla. Tuttavia, se dati alla mano ricalcolassimo oggi un certo parametro, avrebbe dovuto essere in arancione da un mese.
In effetti, analizzando le ultime tre matrici trasmesse a Roma della Lombardia ogni mercoledì, abbiamo trovato dati di scarsa qualità, al punto da rendere inaffidabili alcune stime fondamentali ai fini dell’attribuzione del colore. Parliamo naturalmente del famigerato R(t), che da mesi tiene sulle spine milioni di italiani: nel complesso sistema di attribuzione dei colori alle regioni è certamente il parametro preponderante.
E’ giusto dire da subito che nulla esclude che lo siano anche quelli di altre regioni. Dopo la zona rossa “per errore”, infatti, la Lombardia ha iniziato a pubblicare le matrici degli stati clinici che trasmette all’Istituto Superiore della Sanità ogni mercoledì per il calcolo dell’R(t). Ad oggi però, è ancora l’unica regione a rendere pubblici questi dati.
Perché questi errori? Cosa ci dicono i dati? In questo articolo proveremo a spiegare, in maniera il più possibile comprensibile anche ai non addetti ai lavori, tutte le problematiche che possono inficiare il calcolo di R(t).
R(t), alcune premesse da considerare
Idealmente R(t) è il parametro epidemiologico più adatto per valutare gli effetti delle misure di contenimento dell’epidemia: si definisce come il numero medio effettivo di infezioni (secondarie) derivate da un singolo caso (primario). Senza entrare troppo nel dettaglio, ci fa capire se l’epidemia sta retrocedendo (R(t)<1), è stabile (=1) o in espansione (>1) e, soprattutto, con quale velocità.
Purtroppo, però, avere una stima precisa di R(t) non è cosa semplice. Sempre idealmente, per calcolare R(t) basta una sola variabile: i nuovi contagiati di ogni giorno. L’input nel processo di calcolo sarà quindi una semplice tabella con due colonne: la data di ogni giorno e il numero di nuovi casi corrispondenti a quel giorno.
Il calcolo poi si baserà sul rapporto tra il numero casi di ogni giorno che, ponderato per alcune caratteristiche note e costanti dell’epidemia, ci fornisce R(t).
E’ come se venisse realizzato una specie di “albero genealogico” dei casi: si stabilisce quanti appartengono ad una generazione primaria A, quanti alla generazione successiva B nata dai contatti con la A, quanti alla C, e così via, per poi rapportare tra loro le dimensioni delle generazioni: se la generazione A è più numerosa della B l’epidemia retrocede, mentre se la B è più numerosa della A l’epidemia si espande.
Non è necessario quindi avere chissà quante informazioni: basta avere una “cronologia” delle infezioni. Serve però che questa cronologia sia estremamente precisa: i casi devono infatti essere collocati alla giusta data. Un solo giorno di ritardo nella notifica di un gruppo di casi potrebbe attribuirli a una generazione diversa rispetto a quella a cui appartengono e inficiare così la stima di R(t).
Primo problema: la data
Fin qui tutto abbastanza semplice. Come fare però ad associare ad ogni giorno il numero di nuovi infetti? I nuovi casi comunicati ogni giorno dalla Protezione Civile, ad esempio, si riferiscono alle persone che, tendenzialmente il giorno prima, hanno ricevuto il referto di un tampone positivo. Un eventuale ritardo nella diagnosi o nella refertazione, però, inficerebbe la distanza media tra due generazioni, che quindi non sarebbe più costante nel tempo portando a un dato errato di R(t).
L’ideale, per avere una distanza costante tra generazioni, sarebbe quindi conoscere il numero esatto di persone che ogni giorno entra a contatto col virus. Sapere quando ci si è contagiati, però, non è sempre possibile.
Per ogni caso positivo, i registri di sanità pubblica gestiti dall’Istituto Superiore di Sanità riportano diverse date:
- Data del tampone: il giorno in cui fisicamente viene effettuato il prelievo naso-faringeo;
- Data di notifica: il giorno in cui il caso positivo viene riportato nel registro di sanità pubblica;
- Data di guarigione/decesso: il giorno in cui il caso esce dalla sorveglianza per guarigione o decesso;
- Data di insorgenza sintomi: il giorno in cui il paziente ha sviluppato il primo sintomo;
- Data di ricovero ospedaliero: il giorno in cui il paziente viene ricoverato.
E’ del tutto evidente che nessuna di queste date sarebbe precisa come una ipotetica “data di contagio” per capire quali casi appartengono a quale generazione. In particolare, le prime 3 sono suscettibili di ritardi nella diagnosi, nella refertazione e nella notifica, mentre le ultime 2 non sono disponibili per tutti i casi: non tutti sviluppano sintomi (gli asintomatici non possono avere una data di inizio dei sintomi) e, fortunatamente, solo una minoranza dei casi necessita di ricovero.
Il sistema di monitoraggio che determina il colore delle regioni impiega un R(t) calcolato sulla data di insorgenza dei sintomi, detto R(t)sympt. Tradotto: nella tabella a due colonne da inserire nel processo di calcolo si avrà, accanto a ogni data, il numero di persone positive che quel giorno ha sviluppato il primo sintomo. Questo perché, tra tutte le date a disposizione, è stata ritenuta la più fedele nel riprodurre l’esatta distanza tra le infezioni (qui la spiegazione dell’Istituto Bruno Kessler) considerando un periodo di incubazione medio (distanza tra infezione e sviluppo dei sintomi) di circa 5 giorni.
La data di insorgenza dei sintomi, a differenza, ad esempio, della data di notifica, non è sensibile ai ritardi nella diagnosi e alle politiche sul tracciamento. Per contro, naturalmente, non può considerare i soggetti asintomatici.
Secondo problema: il consolidamento
Una tabella del genere aggiornata ad oggi avrà verosimilmente zero casi nella data odierna. Il motivo è presto detto: un soggetto che per esempio sviluppa sintomi il lunedì, se tutto va bene fa il tampone martedì. Se il tampone è positivo, mercoledì il caso viene riportato nel registro di sanità pubblica. Pertanto, se martedì aprissimo la nostra tabella con i casi per data di insorgenza dei sintomi. nel dato di lunedì il suo caso non ci sarebbe. Mercoledì, invece, troveremmo il suo caso tra quelli accanto alla data di lunedì, perché ha avuto il tampone positivo ed è stato riportato nel registro con la data di insorgenza dei sintomi – per l’appunto lunedì.
Questo se tutto va bene. Sappiamo però che, soprattutto quando il sistema sanitario è sotto forte stress, passano ben più di due giorni tra il primo sintomo e la refertazione di un tampone positivo.
Alla fine, aprendo oggi una tabella con i casi per data di insorgenza dei sintomi, come minimo il numero di casi accanto ai giorni dell’ultima settimana è incompleto: aspettano eventuali altre diagnosi di persone che hanno sviluppato sintomi in questi giorni e devono ancora fare il tampone o riceverne l’esito. Per questa ragione, i dati dei giorni più vicini a quello in cui apriamo questa tabella si dicono “in consolidamento”.
Se sulla tabella aperta oggi andiamo indietro coi giorni, ad esempio a due settimane prima, possiamo dire che pressoché tutti coloro i quali hanno sviluppato i sintomi due settimane fa hanno avuto tempo di fare il tampone e di avere un’eventuale diagnosi positiva. Per questa ragione, R(t)sympt viene calcolato sul dato di 14 giorni prima, ovvero sui primi dati considerati consolidati.
Terzo problema: i campi lasciati in bianco
E’ necessaria un’altra premessa: quando un caso positivo viene registrato, vengono specificate una serie di informazioni. Tra queste:
- Data di insorgenza dei sintomi (se sintomatico);
- Status clinico (asintomatico, lieve, paucisintomatico, severo o grave).
Passato del tempo, ad ogni positivo si aggiungerà l’ultima informazione: guarito o deceduto.
Entrambi i campi di data di insorgenza dei sintomi e di status clinico, però, possono essere lasciati vuoti: quando il medico di base o l’operatore sanitario deve riportare la scheda clinica di un paziente sul portale regionale della sorveglianza, in alcuni casi si può inoltrare la scheda senza inserire nulla in questi campi.
In particolare, è emerso che l’applicativo utilizzato dai medici di base di ATS Città Metropolitana (distretto sanitario che copre le province di Milano e Lodi per un totale di circa un terzo della popolazione regionale) non considera un campo con compilazione obbligatoria lo status clinico del paziente.
Chiarito questo, torniamo alla matrice dati trasmessa a Roma per il calcolo dell’R(t) e alziamo il livello di difficoltà: non c’è solo la colonna della data e quella dei casi che ogni giorno hanno sviluppato i sintomi. Ci sono infatti anche altre colonne che ripartiscono i casi di ogni giorno per status clinico, compresa una colonna di coloro che sono senza status clinico (quelli il cui campo è stato lasciato vuoto), una per quelli guariti e una per quelli deceduti senza mai avere avuto uno status clinico definito.
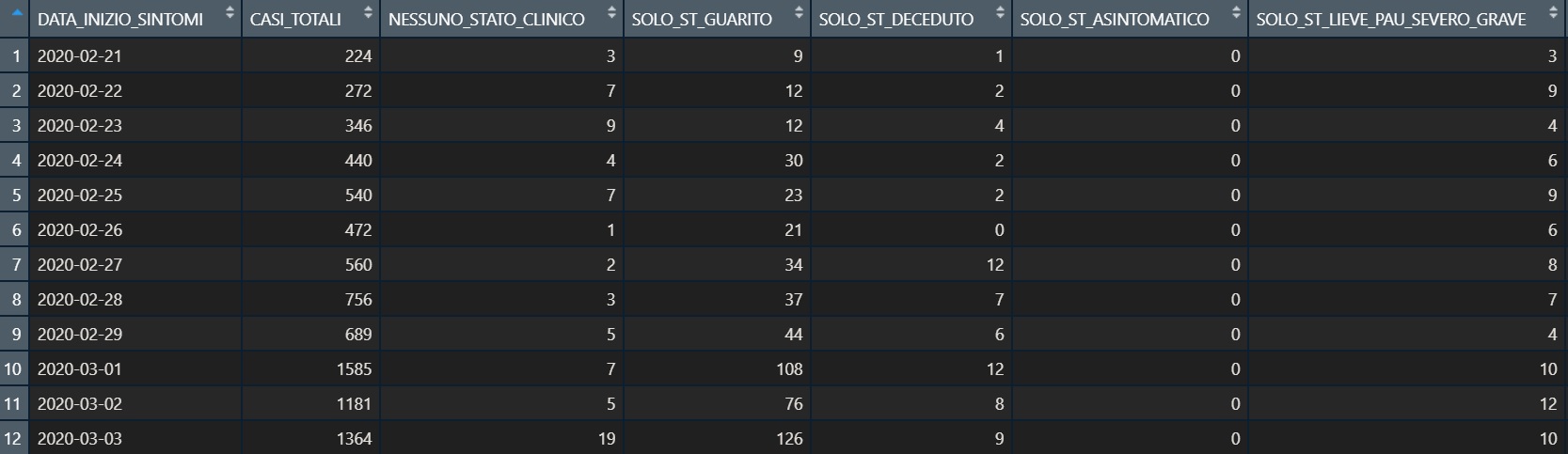
Sarebbe ragionevole presupporre che chi ha una data di insorgenza dei sintomi, come minimo, sia (o sia stato) sintomatico. Facendo varie prove, invece, abbiamo rilevato che se calcolassimo R(t) con il solo numero di persone che ha una data di inizio dei sintomi, otterremmo dati non coincidenti con quelli pubblicati sui bollettini del venerdì.
Per ricavare il valore di R(t) che poi troviamo sui bollettini è necessario fare un’operazione prima di inserirlo nel sistema di calcolo: sottrarre dai casi di ogni giorno la quota di casi guariti che non hanno uno status clinico (campo non compilato). In questo modo, i casi con data di inizio dei sintomi ma senza status clinico escono dal calcolo di R(t)sympt una volta guariti.
Quarto problema: l’assestamento dei casi
I dati di questa serie vengono trasmessi a Roma da tutte le regioni ogni mercoledì. Essendo una serie aggregata per data di inizio dei sintomi, non è possibile inviare soltanto l’aggiornamento dei numeri dell’ultima settimana: ci sono pazienti che vengono inseriti come positivi nel registro mentre hanno avuto il primo sintomo due, tre, quattro (un classico della prima ondata) settimane prima. In questo caso è necessario incrementare il dato riferito a diversi giorni indietro.
Per questa ragione, a Roma ogni mercoledì arriva una nuova serie che sostituisce la precedente in tutti i suoi valori, dal 21 febbraio 2020. Inoltre il portale open data di Regione Lombardia riporta la seguente frase: “Si segnala che i dataset pubblicati possono contenere errori di consistenza interna dovuti a imprecisioni nel data entry di alcune date da parte di operatori sanitari, che risentono di un processo di raccolta dati vasto e articolato”.
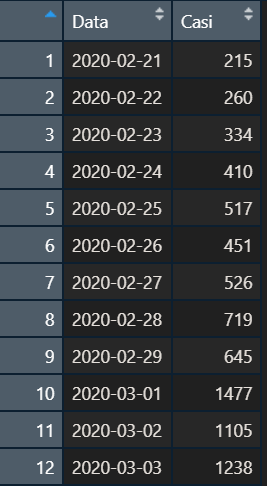
Tutto ciò premesso, ci sono numerose discrepanze davvero difficili da comprendere. Prendiamo ad esempio il giorno del primo tampone positivo a Codogno, il 21 febbraio 2020. Nella matrice dati trasmessa a Roma mercoledì 24 febbraio 2021, i pazienti che hanno avuto il primo sintomo il 21 febbraio 2020 risultavano essere 219, nella matrice trasmessa il mercoledì seguente risultavano 224.
Sul giorno seguente, il 22 febbraio 2020, nella matrice trasmessa mercoledì 24 febbraio 2021 si hanno 262 insorgenze di sintomi, nella matrice trasmessa il mercoledì seguente 10 in più, 272. Ciò significherebbe che tra il 27 febbraio ed il 2 marzo 2021, sono stati refertati per la prima volta tamponi positivi a persone che hanno avuto il primo sintomo più di un anno prima!
Ci sono anche dei cali: il 1° maggio 2020 tra la matrice del 24 febbraio e quella del 3 marzo si perdono 3 casi, ma di esempi ce ne sono tanti. Anche questo processo costante di assestamento contribuisce quindi ad inficiare il rapporto tra le dimensioni delle generazioni di contagi, e quindi l’R(t).
Errori nell’attribuzione dei colori: il caso Lombardia
Dopo aver parlato a lungo di cause, ora vediamo le conseguenze.
Abbiamo salvato le ultime tre serie di dati trasmesse a Roma dalla Regione Lombardia per il monitoraggio settimanale. Basandoci sul procedimento reso pubblico dall’Istituto Superiore di Sanità abbiamo calcolato R(t) su tutte e tre le serie.
E’ emerso che i dati sono utili per calcolare l’R(t) puntuale che viene pubblicato sul bollettino del venerdì seguente, ma se li utilizzassimo per ricalcolare gli R(t) dei bollettini precedenti otterremmo dei valori pressoché sempre diversi da quelli riportati in ogni bollettino, anche significativamente diversi.
Per esempio, l’R(t) che ha messo la Lombardia in zona rossa “per errore” col bollettino del 15 gennaio, poi ricalcolato la settimana seguente con un risultato da zona gialla, se venisse ricalcolato sulla serie dati di mercoledì 24 febbraio darebbe di nuovo dei valori da zona rossa, mentre su quella di mercoledì 3 marzo darebbe numeri da zona arancione.
Gli R(t) puntuali riportati in tutti i bollettini di febbraio erano da zona gialla (compreso l’ultimo, che poi ha portato comunque la Lombardia in arancione per livello di rischio alto). Se ricalcolati oggi, invece, sarebbero tutti da arancione.
Conclusione
Una scarsa attenzione alle problematiche sin qui elencate porta ad alterare inutilmente il delicatissimo equilibrio tra contrasto alla pandemia, tutela dell’economia e salute mentale della popolazione, equilibrio che da più di un anno stiamo cercando di inseguire.
Certo, sarebbe auspicabile che tutte le altre regioni, o il Ministero stesso, rendano pubblici questi dati. A Palazzo Lombardia si sono accorti che qualcosa non torna, tant’è che nel bollettino dello scorso venerdì appare una nota dove si specifica che R(t) è calcolato su dati “in consolidamento”.
D’altra parte, dovrebbero essere problematiche note a chi ha a che fare quotidianamente con tutto questo: un sistema di monitoraggio così delineato lascia ampio spazio a margini di errore, fisiologici e non, nella articolatissima fase di raccolta e inserimento dei dati. Ma questo non è comunque l’unico appunto che si potrebbe fare per stimolare una revisione complessiva di un sistema di monitoraggio tanto unico al mondo quanto ampiamente perfettibile.
Commenta